
Murugan
Blog by Murugan

License slaves report usage every minute to the manager. After 72+ hours of no contact, a slave violates and blocks searches but allows indexing. Users can't search the violating slave until it reconnects with the manager.
18.07.24 08:14 PM - Comment(s)

The Data from the source will not be forwarded to the indexer. As soon as the forwarder comes up, it will continue the streaming of data.
17.07.24 08:11 PM - Comment(s)

Deployment clients (e.g., forwarders) cannot fetch app updates or checksums. Forwarders operate normally but cannot receive new configurations until the server is restored, impacting deployment of updates.
16.07.24 08:08 PM - Comment(s)

No major issues to the environment's data flow. searches will work normally; indexing will happen as usual. The only issue is the admin or whoever was using the Monitoring Console to track and monitor the health of Splunk Environment, will lose the visibility.
15.07.24 08:06 PM - Comment(s)
You cannot push new configurations to the members. • A member that joins or rejoins the cluster, or restarts, cannot pull the latest set of apps tar balls.
14.07.24 08:01 PM - Comment(s)

Issue:
- A few events are missing in Splunk Cloud. Most of the data is being ingested as expected. Missing events that should be forwarded by the forwarder, UF or HF. This issue happens intermittently.
Root Cause:
- Splunk forwarder queues are saturated. When it was released Splunk tailreader went to r...
14.07.24 01:46 PM - Comment(s)
This will show nothing to users, probably user will get “The site can’t be reached” or “502 Bad Gateway” error when they try to access the Instances URL or the Load balancer URL. Peers can continue ingesting the data as they are not dependent on the search heads.
13.07.24 07:59 PM - Comment(s)
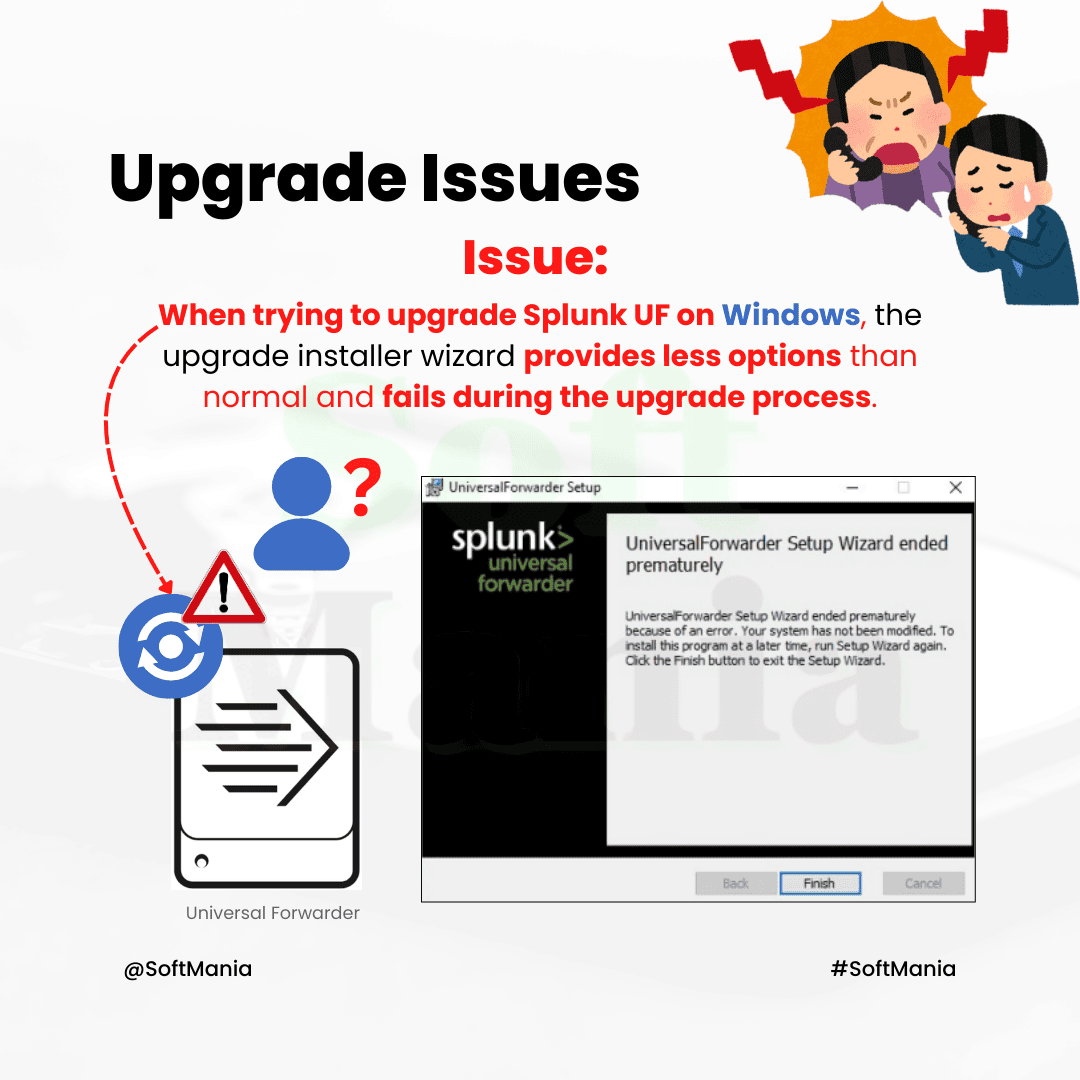
Issue:
- When trying to upgrade Splunk UF on Windows, the upgrade installer wizard provides less options than normal and fails during the upgrade process.
Root Cause:
- Bad/corrupted registry entry within Windows which may even get deployed to multiple systems via Windows SCCM (System Center Configurat...
13.07.24 01:03 PM - Comment(s)
If a majority of members fail, the cluster may be unable to elect a new captain, resulting in cluster failure. To ensure continuity, configure the remaining member as a static captain to maintain operational stability despite the loss of majority nodes.
12.07.24 07:56 PM - Comment(s)

Search artifacts from the failed member remain accessible through other search heads. With only 2 nodes, if the failed member was the captain, configuring one as a Static captain and the other as a member ensures seamless functionality and ongoing operational stability.
11.07.24 07:49 PM - Comment(s)

Issue:
- After upgrading UF to 9.1.2, data ingestion issues were found. Reverting to the previous version works fine. Data flow is stopped.
Root Cause:
- Version 9.1 and above are installed by default with a VSA (virtual service account), which can cause problems with certain paths and resources.
Soluti...
11.07.24 12:57 PM - Comment(s)
The Cluster Master shows all members as down, indicating the cluster's inactive status. Search heads cannot retrieve data, as no Indexers can process queries. Forwarders accumulate data, causing increased queues until Indexers are restored, impacting data flow and system performance.
10.07.24 07:45 PM - Comment(s)

- Searches may return incomplete results until all bucket copies on surviving Indexers are made searchable. - The Cluster Master directs surviving peers to make all available bucket copies searchable, including promoting them to primary copies by indexing raw data.
09.07.24 07:43 PM - Comment(s)

- Searches can continue but may yield partial results until the cluster is fully operational. - Bucket-fixing (repairing data sets) is managed by the Cluster Master once it's restored. - Replication to and from the offline peer stops until it reconnects, impacting data consistency and redundancy.
08.07.24 07:37 PM - Comment(s)

Indexers and search heads operate normally but can't perform cluster management tasks. Search heads warn of peer node issues. No coordination for bucket fixes if peers are down. Forwarders can't forward data without cluster info, risking data loss.
07.07.24 07:34 PM - Comment(s)

Issue:
- After upgrading to Splunk UF to v9.1.3 version, data flow is happening, but Windows instance is exhausting the CPU.
Root Cause:
- Version 9.1 and above are installed by default with a VSA (virtual service account), which can cause problems with certain paths and resources.
Solution:
- Enable the...
07.07.24 01:00 PM - Comment(s)

Issue:
- Splunk Add-on for Salesforce is unable to make API calls and no data is collected from the Forwarder. (Error messages from Add-on)
Root Cause:
- KV Store is down. Splunk Add-on for Salesforce uses the KV Store service in data collection, so KV Store should be up and running. The License is not...
07.07.24 12:54 PM - Comment(s)

Issue:
- Data cloning from a forwarder to two different indexers, there are gaps of data in one of the indexes, both receive the data but one of them maintains a latency.
Root Cause:
- Forwarder’s throughput was limited, so it is not able to send data to both of the indexers with proper cloning
INFO Tai...
07.07.24 12:50 PM - Comment(s)

Issue:
After Migration to cloud, On-Prem forwarders are not able to connect properly. (HTTP Event Collector Connection Fails)
Root Cause:
- Splunk App for Stream is not able to generate and detect HEC tokens automatically.
Solution:
- Need to do fresh installation of “Splunk App for Stream“ without putti...
07.07.24 12:43 PM - Comment(s)
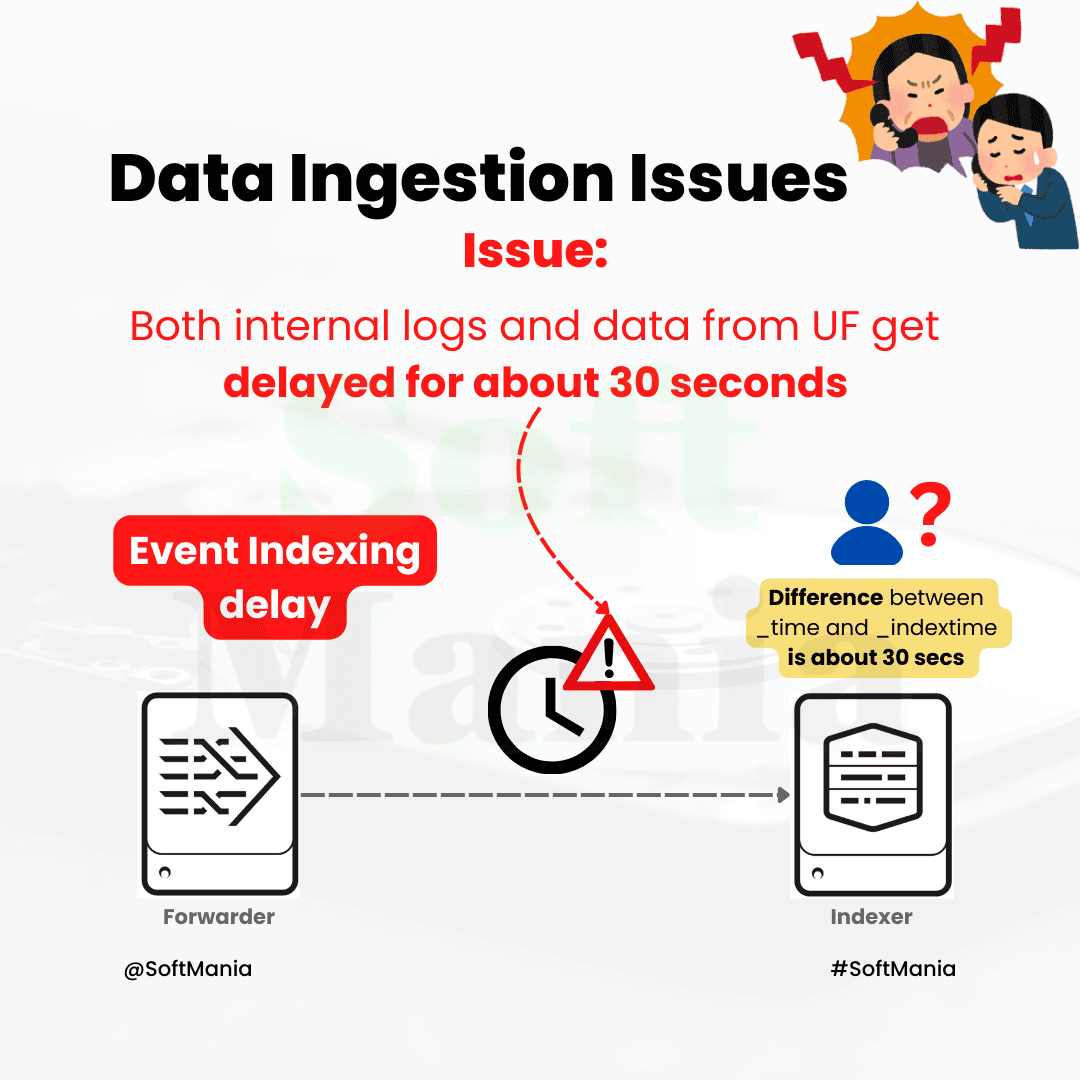
Issue:
- Both internal logs and data from UF get delayed for about 30 seconds. (Event Indexing delay)
- Difference between _time and _indextime is about 30 seconds.
Root Cause:
- UF processes a larger number of files than it typically does.
- Increased size of the fishbucket & the processing of...
07.07.24 12:24 PM - Comment(s)
Categories
Tags
- Data Replication Issues
- Data Frowarding Issues
- App Deployment Issues
- Indexers down 3-member cluster
- Two Indexers down 3-member cluster
- All Indexers down 3-member cluster
- Search Heads down 3-member cluster
- Two Search heads down 3-member cluster
- All Search Heads down 3-member cluster
- Deployer is down
- Monitoring Console down
- Deployment Server down
- Universal Forwarder down
- License Server/Manager down
- Decide number Search Heads & Indexers
- how to choose forwarder (UF or HF)
- Intermediate Forwarder (IF))
- Licence Forwarders
- can't use single instance with huge size instead separatly
- How splunk stores Indexes
- Possible open flat files in Notepad++
- Possible rename index
- clean index splunk instances & indexer cluster
- Migrate index 1 splunk server to another splunk server
- Backup splunk configuration/data
- upgrade splunk enterprise
- upgrade splunk enterprise which clustered
- Upgrade the Splunk Universal Forwarder
- Deploy apps to search head clusters
- Deploy Apps indexer Cluster
- Connect Forwarders to indexer cluster
- Difference between Heavy forwarders & HTTP Event collector
- Cluster Master is down Then need a cluster master
- colocation of splunk components
- meant colocation splunk components
- Deployment server to distribute apps to search head cluster & indexer
- reduce licence in splunk
- why need license master/server
- Replication Factor lower than search factor
- Timestamp Issues
- Event Truncation Issues
- Retention Plicy Issues
- SAML Issues
- Parsing Issues
- File Monitoring Issue
- Configuration Issue
- Summary Index Issues
- Deployment Issues